اليوم حنتكلم عن Elasticsearch (ES)، وحنغطي مفاهيم كثيرة سوا. المقالة تفترض انك تعرف اساسيات عن قواعد البيانات وعندك فكرة عن تطوير البرمجيات وقيد اتعاملت مع live production systems.
لو كنت تحتاج مراجعة بسيطة، هذه مقالة كتبتها حتساعدك كثير: مفاهيم قواعد بيانات (databases) مهمة لكل شخص تقني
![]()
ايش حنشوف ونتعلم سوا اليوم؟
- ايش Elasticsearch، وليش احتاج هذه التقنية؟ 🤔
- كيف Elasticsearch يسمي الأشياء؟ 📝
- نبدأ الرحلة: Index Creation 🚀
- الزبدة 🧈
ايش Elasticsearch، وليش احتاج هذه التقنية؟ 🤔
لو كنت تتعامل مع بيانات كبيرة (فيها الـ3Vs of Big Data) او حتى بس بيانات عشوائية (مثلا من عملية scraping او صادرة من logs)، فغالبا تعرف عناء التحكم في صحة البيانات والبحث فيها بشكل فعال. مو بس كدا، كمان فكرة انه انت فالغالب ما تتحكم في مصدر البيانات هذا (او ما تبغا تقننه)، مما يمحي خيار انك تستخدم SQL database، وضيف على كدا انك ما تدري كيف حتستخدم هذه البيانات (او حتى اذا فيها شي مفيد او لا). فصعب عليك انك حتى تحط Partition key او Sort Keys في اي NoSQL database تستخدمها.
اتكلمت اكثر عن الـNoSQL database وكيف تحفظ البيانات هنا
لو هذه فعلا مشكلة تواجهها، كمل قراءة.
Elasticsearch هو Schemaless database وكمان محرك بحث (search engine)، يعني اثنين في واحد. 🔋
مبنية باستخدام Java ومحرك بحث اسمه Lucene. وعشان تستخدم Elasticsearch, مو لازم تعرف لا Java ولا Lucene، فلا تشيل هم. :)
كل شيء في Elasticsearch سواء ادخال البيانات، البحث، استخدام البيانات، او عمل aggregations يصير عن طريق REST APIs. وهذا ميزة رهيبة تسمح ان عدد اكبر من الناس يستخدم ES بسهولة وتقدر تربط معاها عن طريق اي لغة فيها http client.
فبكل بساطة، Elasticsearch هو عبارة عن استخدام صحيح لـLucene كـschemeless database ومحرك بحث، مكتوب عن طريق Java، ومُسهّل استخدامه عن طريق REST APIs وفيه ميزات تشغيلية اخرى.
فالغالب، Elasticsearch يستخدم مع تقنيات ثانية تسمى بـElastic Stack، حنتكلم اكثر عنها في آخر جزء في المقالة الثالثة من السلسلة
ايش فيه استخدامات شائعة لـElasticsearch؟
ES لاقى رضى الناس في كثير من المجالات، حتكلم عن اكثرها شيوعا هنا، وعليك انك تتخيل كيف ممكن تستخدم كمان:
Log aggregation
حتى او ما تعرف الا شويه عن Elasticsearch، هذا قد يكون اول شي يجي في بالك. اللوقز مثال تطبيقي رائع لبيانات كثيرة، مانتحكم فيها، ما نبغا نقننها، وما نعرف اذا وكيف حنستخدمها. مما يجعل فكرة انك تدخل كل الـlogs في ES عشان تبحث فيها لو احتجت فكرة ممتازة. وغالبا طريق الـstreaming للـlogs تكون باستخدام خدمات ثانية مثل Logstash او Fluentd
محرك بحث داخل التطبيقات
بما ان كل التواصل مع Elasticsearch يصير عن طريق الـREST APIs، كملوها مطورين المحرك وخلوا انك تقدر تضيف بعض الـquery parameters و شويه configuration عشان يصير البحث في منتجك يستخدم Elasticsearch. خلينا نتخيل ان عندك متجر الكتروني، وتبغا الناس تقدر تبحث في اي معلومة موجودة في المنتجات اللي عندك. مو بس كدا! تبغا حتى تمشيلهم الاخطاء الاملائية و/او تعتبر بعض الحروف نفس الحرف (مثلا احمد و أحمد يصيروا نفس الكلمة). تقدر تسوي هذه الخاصية بكل سهولة مع Elasticsearch بإنك تدخل منتجاتك وجميع معلوماتها في index وتخلي البحث عليه. واضيف لك انك حتى تقدر تخلي Elasticsearch يقولك لك ليش هذا المنتج مقارب للكلمة اللي كتبها المستخدم عن طريق تظليل الناتج من الـquery.
واحدة من اكبر الشركات اللي تستخدم Elasticsearch بشكل فعال هي Stackoverflow. فالتقنية تعتبر جدا ناجحة وناضجة في مجال البحث.
اكتشاف ثغرات امنية
يجي مع البطاريات كمان خدمات مختلفة مخصصة لامن الخدمات. الصراحة ماعندي تجربه سابقة بيها، ولكن كل شيء تحتاج تعرفه (IPs, endpoints, ports, etc.) عن اي خدمة (لو سويت الربط صح) ممكن يجيك عن طريق ES ويخليك تعرف ايش بيصير في اي واحدة من خدماتك ولو فيه حاجة خارجة عن المألوف.
مركز بيانات لتدريب نماذج تعلم الآلة (Machine Learning)
تخيل ان قدرنا نعطيك مكب كبير للبيانات فيه ملايين الصفوف، وعندك لها schema مبدئية، وتقدر تبحث فيها بأي كلمة وبأي عامود، وتقدر حتى تتغاضى عن الاخطاء الاملائية، او تبحث بالكلمات اللي تشبه بعض، او حتى لها نفس المعنى (مثلا مصباح ولمبة). الآن وري الجملة اللي فاتت لـmachine learning engineer عندكم يشتغل على NLP task وبيقلك هذا فالجنة ان شاء الله. 😂
ولكن ES حل ممكن فعلا يعطيهم اللي فوق، فاستخدام شائع ورهيب جدا هو ان ES يكون قاعدة بيانات يقدروا يرجعوا لها data scientists او غيرهم في فريق البيانات ويستخرجوا datasets ممكن تساعدهم في تدريب او اختبار نماذجهم بشكل سهل وسريع.
متى خطأ تستخدم Elasticsearch؟ ❌
من المكتوب فوق، حتبدأ تحس ان ES عبارة عن database معضلة تقدر تسوي كل شي. ولكن الفكرة هذة خطأ جدا. استخدامك لهذه التقنية -مثل كل التقنيات- سلاح ذو حدين وفيه كثير tradeoffs قد تكون في غنى عنها ولا تحتاجها. هذه بعض المواضيع اللي خطأ يستخدم ES لحلها:
Relational Database
لو عندك تطبيق، وعندك له entities، وفيه بين الـentities علاقات او relationships، لا تستخدم Elasticsearch. مافيه طريقة بسيطة عشان تجمع البيانات، والتقنية تعتمد على ان كل document تدخله يكون مكتفي ذاتيا (self contained). فيه طريقة توفرها لك ES لو كنت مره مضطر، ولكن حتى هما كاتبين ان استخدام هذه الميزة ما يعتبر best practice.
ودائما اسأل نفسك: PostgreSQL فإيش قصرت معاك؟ :)
Transactional Database
لو تهتم بالـACID guarantees، اهرب، ES مو الحل الصحيح. برضه PostgreSQL فايش قصرت؟ 😂
بعيدا عن المزح، ES مصممة انها تكون distirbuted من البداية، فوحدة من القرارات المعمارية اللي اتخذوها مطورين ES هي ان البانات تكون Eventually Consistent. فلا تتوقع انك تقدر تستخدمها عشان تخدم مستخدمين بشكل مباشر (الا في حالات محددة جدا مثل البحث).
لو تبغا تعرف اكثر عن الـeventual consistency، اتكلمنا عنها انا وعبدالرحمن في حلقة من حلقات بيفابت. تقدر تلاقي الشرح هنا
لو عندك عمليات كتابة كبيرة وسريعة
لا تدخل البيانات في Elasticsearch بشكل سريع جدا، لانها مصممة على القراءة السريعة وليس الكتابة. لو كان عندك بيانات تجيك على شكل stream، استخدم شيء يدخل البيانات بشكل batches مثل Flume او Kafka، ومن الافضل انك تستخدم خواص الـbatch ingestion في ES.
تبغا تحفظ بيانات كبيرة Binary
تقدر تدور على كم هائل جدا من الـtext data على ES، ولكن ليست الحل الصحيح لو تبغا تدور عن معلومات في الصور او الفيديوهات. اتسخدم Amazon S3, Azure Blob Storage، MinIO، او غيرهم لو تبغا تحفظ Binary data.
حلو جدا، غطينا ايش Elasticsearch، متى يستخدم، ومتى ما يستخدم. بما انك لسى هنا، افترض انك تبغا تستخدم ES وعندك سيناريو مناسب، فخلينا ندخل على ايش المفاهيم الضروري تعرفها عشان تبدأ تستخدم هذه التقنية الجميلة بشكل فعال. 🚀
كيف Elasticsearch يسمي الأشياء؟ 📝
روعة، الآن خلينا نعرف بعض العناصر اللي تكون Elasticsearch وتستخدم بشكل كبير جدا. معرفتك لمعنى كل واحدة من هذه المصطلحات حيساعدك كثير تدور في Google وتقرأ الـdocumentation وتفهم ايش المقصد بسهولة.
Index
الـIndex هو المكان اللي يتم فيه تخزين البيانات في Elasticsearch. تقدر تفكر فيه كأنه table في قواعد البيانات التقليدية. كل مجموعة من البيانات اللي لها علاقة ببعضها يتم تخزينها في Index، وممكن يكون عندك أكثر من Index في نفس النظام.
Mapping
الـMapping هو الطريقة اللي فيها تحدد كيف يتم تخزين البيانات وفهرستها داخل الـIndex. يعني تحدد نوع البيانات (مثل نص، رقم، تاريخ) وكيفية التعامل معها. الـMapping ضروري عشان تتحكم في كيفية البحث في البيانات واسترجاعها بكفاءة. تخيل انها الـschema للـindex.
ممكن الآن تسأل، مو احنا قلنا انها Schemaless؟ صحيح، ES ما تفرض عليك انك تعرف schema وتعتمد على الـtype inference عشان تعرف كل حقل من حقول الـdocuments اللي تدخلها لقاعدة البيانات ايش نوعه. حنتكلم اكثر عن الـtypes inference في الجزء الثالث من السلسلة.
Documents
الـDocuments هي الوحدة الأساسية لتخزين البيانات داخل Elasticsearch. كل Document يحتوي على بيانات في شكل JSON ويتم تخزينه داخل Index. الـDocuments مرنة وقابلة للتوسيع، تقدر تضيف أو تغير البيانات بكل سهولة بدون الحاجة لتغيير هيكل (schema) البيانات بالكامل.
تقدر تتخيل ان كل document هو عبارة عن row فالـrelational models. ومن المهم انك تحاول يكون كل document مكتفي بذاته وما عنده علاقات بـdocuments اخرى.
Alias
الـAlias هو اسم مستعار يمكن استخدامه للإشارة إلى واحد أو أكثر من الـIndices (جمع Index). الفائدة من الـAlias هي أنك تقدر تعمل تغييرات على الـIndices بدون ما تأثر على التطبيقات اللي تستخدمها، لأنها تستخدم الـAlias بدلاً من اسم الـIndex مباشرة. هذا يعزز المرونة ويسهل عمليات إدارة الـIndices في الوقت الفعلي. فدائما لما تسوي تكامل (integration) مع ES، استخدم Alias، عشان تكون عندك الحرية تغير الـindex او تضيف index آخر معاه بكل سهولة بدون ما تغير اي كود بره Elasticsearch.
Cluster
الـCluster في Elasticsearch هو عبارة عن مجموعة من الـNodes اللي يشتغلوا مع بعض لتحقيق الأهداف المطلوبة. الـCluster يضمن لك توزيع البيانات والمعالجة بشكل متساوي بين الـNodes المختلفة، وهذا يساعد في تحقيق الأداء العالي والمرونة في التعامل مع البيانات الكبيرة.
Full-Text & Fuzzy Search
البحث النصي الكامل (Full-Text Search) هو البحث في كامل النصوص المخزنة في Elasticsearch. هذا النوع من البحث يسمح لك بإيجاد كلمات وعبارات داخل النصوص بكل سهولة. البحث الضبابي (Fuzzy Search) هو نوع من البحث اللي يسمح بإيجاد كلمات مشابهة للكلمة اللي بحثت عنها حتى لو كان فيها أخطاء إملائية بسيطة أو اختلافات طفيفة. وهذه الميزة هي اللي تخلينا نحقق بعض النتائج اللي اتكلمنا عنها في بداية المقالة.
نبدأ الرحلة: Index Creation 🚀
الآن بعد ما عرفنا ايش هو الـIndex، خلينا نبدأ في كيفية إنشاءه في Elasticsearch. الـIndex هو العنصر الأساسي اللي نخزن فيه بياناتنا في Elasticsearch، ولكل Index لازم يكون عندنا Mapping يحدد كيف البيانات هذي راح تتخزن وتنظم. عملية إنشاء Index تبدو بسيطة، لكن تحتاج تركيز على التفاصيل لضمان كفاءة الأداء وما تزعل من نفسك مستقبلا.
نقطة مهمة: الامثلة هنا في كل السلسلة تفترض على انه عندك Elasticsearch يشتغل، وجميع الأمثلة مكتوبة على Kibana Dev Tools.
تقدر تعرف اكثر هنا
كيف اسوي Index
عشان نسوي Index في Elasticsearch، نستخدم الـREST API اللي يوفره Elasticsearch. العملية تتم عبر إرسال طلب HTTP من نوع PUT للـAPI (تستخدم address الـcluster هنا) مع تحديد اسم الـIndex اللي نبغى نسويه. فيه مجموعة من الـparameters اللي لازم يكون الشخص على علم بها وقت إنشاء الـIndex، مثل إعدادات الـShards والـReplicas (حنتكلم عنها في الجزء الثاني من السلسلة: Elasticsearch الجزء الثاني: خلينا نعيد تعريف البحث في قواعد البيانات للأبد) اللي تأثر على كيفية توزيع البيانات عبر الـCluster وكفاءتها.
مثال بسيط لعملية إنشاء Index:
PUT /my_new_index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
هنا حددنا عدد الـShards والـReplicas، وهذي من أهم الإعدادات اللي تحدد كفاءة توزيع البيانات واسترجاعها. تقدر تتدرب وتتكلم مع Elasticsearch بكل سهولة عن طريق الـdev tools في Kibana. والامثلة في المقالة حتكون مبنية عليها، عشان كدا ما حتكون cURL او شي قد تكون متعود عليه.
انواع البيانات واهميتها، وكيف تسوي Mapping صحيح
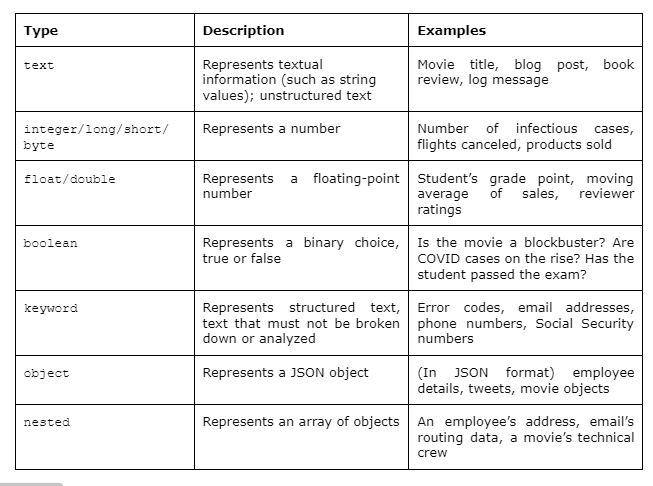
في Elasticsearch، فيه عدة أنواع من البيانات اللي تقدر تخزنها، وكل نوع له استخدامه وأهميته. أهم الأنواع تشمل:
- Text: النوع الأكثر استخدامًا لتخزين النصوص الصغيرة او الكبيرة اللي تحتاج عمليات بحث متقدمة وتكون غير منتظمة.
- Keyword: لتخزين نصوص قصيرة غير قابلة للتحليل ومنتظمة، مثل الايميلات، ارقام الجوال، او اسماء المدن. النصوص هذه مالها معنى لغوي كبير.
- Numeric: لتخزين الأرقام بأنواعها المختلفة، سواء كانت أعداد صحيحة أو عشرية (float).
- Date: لتخزين البيانات الزمنية بتنسيقات مختلفة. ولكن ES فالغالب يتوقع ISO 8601
- Object: لتخزين هياكل بيانات معقدة مثل JSON، حيث يتم التعامل مع الحقول الداخلية كجزء من الـDocument. تقدر تستخدم هذا النوع من البيانات عشان تدخل JSON objects جوا بعض. خلي في بالك ان هذا النوع من البيانات ما يفصل الـkeys و الـvalues (حنتكلم زيادة عن الموضوع).
- Nested: مشابه للـObject، لكن مع فرق أنه يعامل كل عنصر داخله كـDocument منفصل لتحسين دقة الاستعلامات المعقدة. هذا نوع ياخذ مساحة اكثر ولكن يفرق بين الـkeys والـvalues حقتها.
الفرق بين Text و Keyword مهم جدًا. Text يستخدم لتخزين النصوص اللي تحتاج إلى تحليل وتفكيك (مثل البحث بالكلمات المشابهة أو البحث النصي الكامل او الـfuzzy search)، وعادةً ما يستخدم في الحقول اللي تحتاج لبحث معقد. بينما Keyword يستخدم لتخزين النصوص القصيرة غير القابلة للتحليل ويكون مثالي عندما تحتاج لمطابقة دقيقة بدون أي تحليل للنص. فمثلا، تستخدم keyword للايميلات، لان ما تبغا الايميلات اللي تشبه ايميل معين، بل فالغالب تبغا فقط الايميلات المطابقة لبحثك.
أما بالنسبة للـObject و Nested، الفرق يكمن في كيفية التعامل مع البيانات المتداخلة. Object يعامل الحقول الداخلية كجزء من نفس الـDocument، مما قد يؤدي إلى نتائج غير دقيقة عند إجراء عمليات البحث. بينما Nested يعامل كل عنصر داخل الهيكل كأنه Document منفصل، مما يوفر دقة أكبر في الاستعلامات المعقدة اللي تتطلب التعامل مع البيانات المتداخلة بشكل صحيح.
خلينا نوضحها اكثر بمثال: لو عندي الـobject التالي:
{
"name": "Mohammed Ghawanni",
"address":
{
"city":"Medinah",
"street":"Prince Abdulmajeed",
"district": "Al-Ehen"
}
لو خلينا الـadderess نوعه object، ما حيقدر يفرق لو ان “Medinah” هي city ولا street ولا address. بينما لو كان nested, حيكون العلاقات محفوظة بنفس الطريقة اللي دخلناها فيها (كل مفتاح له قيمته).
وهذه صورة (المصدر) تورينا الفرق بين انواع الحقول في Elasticsearch على شكل جدول مع امثلة.
إيش الأشياء المهم انتبه لها وقت الـMapping؟
عند إنشاء الـMapping للـIndex، لازم تأخذ في بالك عدة أشياء لضمان أن البيانات راح تتخزن وتكون مفهرسة بطريقة صحيحة. من الأمور اللي لازم تنتبه لها هي نوع البيانات اللي راح تخزنها وكيف راح يتم فهرستها. من الاستخدامات اللي تصير كثير، هو أنه بعض الأحيان يقوم الشخص المسؤول عن الـCluster بعملية ingestion للبيانات بدون تحديد الـMapping أولًا، وبعدها يعدل الـMapping حسب الحاجة، ويعمل Re-index إلى Index جديد. هذا الإجراء ممكن يكون مفيد في بعض الحالات، لكنه ممكن يزيد من تعقيد الأمور ويحتاج إلى موارد إضافية.
هذه الطريقة اللي تسوي من خلالها mapping وتعرفه في الـindex:
PUT /my_index
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"email": {
"type": "keyword"
},
"age": {
"type": "integer"
},
"created_at": {
"type": "date"
},
"address": {
"type": "object"
},
"tags": {
"type": "nested"
}
}
}
}
هذا الكود ينشئ Index اسمه my_index ويحدد الـmapping بحيث يشمل عدة أنواع بيانات: text، keyword، integer، date، object، وnested. هذا الـmapping ضروري لضمان تخزين البيانات بطريقة منظمة وفعالة.
اضافة بيانات داخل الـindex
اضافة البيانات داخل الـindex طبعا شي اساسي ومطلوب. فيه كم طريقة تدخل بيانات، اسهلها تكون عن طريق الـAPI اللي فيه اسم الـindex وباستخدام POST
POST /my_index/_doc/1
{
"name": "Mohammed Ghawanni",
"email": "mohammed@example.com",
"age": 28,
"created_at": "2024-08-22",
"address": {
"city": "Medinah",
"street": "Prince Abdulmajeed",
"district": "Al-Ehen"
},
"tags": [
{
"tag": "elasticsearch",
"importance": "high"
},
{
"tag": "kibana",
"importance": "medium"
}
]
}
في هذا المثال، نضيف Document جديد للـIndex اللي أنشأناه. لاحظ كيف البيانات تتوافق مع الـmapping اللي حددناه في البداية. address هو object عادي وtags هو nested array من objects.
تقدر كمان تدخل البيانات بالجملة على الـindex تبعك عن طريق استخدام
bulk_، تقدر تلاقي الطريقة والـdocumentation هنا.
Re-indexing: واحدة من أهم العمليات
الـRe-indexing عملية حساسة جدًا في Elasticsearch. إذا كان عندك بيانات موجودة في Index معين، وقررت تغير الـMapping أو أي من الإعدادات، تحتاج تعمل Re-index، وهذا صحيح برضه في حال تغيير عدد الـshards.
الـRe-indexing يعني بكل بساطة أنك تنسخ البيانات من Index قديم إلى Index جديد مع إعدادات أو Mapping مختلف. هذه العملية مهمة جدا لما تحتاج تعدل كيفية تخزين أو فهرسة البيانات بدون فقدانها.
لكن لازم تنتبه! عملية الـRe-indexing تتطلب توقف استخدام الـCluster لأنها ممكن تسبب تعارضات إذا كانت البيانات في حالة تحديث مستمر. لذلك، يفضل دائمًا تخطيط عملية الـRe-indexing بدقة لتجنب أي مشاكل، لانها (بحسب كبر البيانات) ممكن تاخذ وقت مو بسيط.
POST /_re-index
{
"source": {
"index": "old_index"
},
"dest": {
"index": "new_index"
}
}
هذا الكود ينقل البيانات من old_index إلى new_index. تقدر تستخدم هذا الأمر لو كنت تحتاج تغير الـMapping أو حتى تحديث بيانات معينة بطريقة أكثر فعالية. فالـmapping الجديد بيكون على new_index. وعشان هذه العملية تكون سلسة اكثر، نقدر نستخدم Alias الى حين انتهاء الـRe-indexing
عمل Alias للـIndex واستخدامه
الـAlias هو اسم مستعار تقدر تستخدمه للإشارة إلى Index أو مجموعة من الـIndices. أهمية الـAlias تظهر بشكل كبير لما تحتاج تعمل تغييرات على الـIndices بدون ما تأثر على التطبيقات اللي تستخدمها. مثلا، إذا كنت تحتاج تغير اسم Index أو حتى تعمل Re-index للبيانات، تقدر تخلي التطبيقات تستمر في العمل بدون انقطاع باستخدام Alias.
مثال على حالة استخدام الـAlias: لو عندك Index بيتم تحديثه باستمرار وتحتاج تعمل Re-index، تقدر تعمل Alias للـIndex القديم وبعد ما تنتهي من الـRe-index، تغير الـAlias ليشير إلى الـIndex الجديد، وبكدا تكون التطبيقات اللي تعتمد على الـIndex شغالة بدون ما تحس بأي انقطاع أو تغيير.
//القديم
POST /_aliases
{
"actions": [
{
"add": {
"index": "old_index",
"alias": "current_index"
}
}
]
}
// تغيير الاسم المستعار يأشر على اي index
POST /_aliases
{
"actions": [
{
"remove": {
"index": "old_index",
"alias": "current_index"
},
"add": {
"index": "new_index",
"alias": "current_index"
}
}
]
}
في هذا المثال، سونا Alias اسمه current_index يأشر على old_index. بعد عملية الـRe-index، نحدث الـAlias عشان يأشر على new_index بدون ما تتأثر التطبيقات اللي تعتمد على الـIndex لانها تستخدم current_index اللي هو alias؛ فالتطبيقات حتى ما عرفت ان الـindex اتغير.
الزبدة 🧈
والله ابغا اخدمك، بس صعب اكتب زبدة لهذه المقالة. حاول تقراها. :) 3>
حاكون ممتن لو ساعدتني على نشر العمل هذا عن طريق ارسال المدونة لاحد ممكن يستفيد منها، فالاخير الهدف هو نشر محتوى عربي تقني بجودة عالية مجانا؛ مساعدتك لي في هذا الهدف يعني لي الكثير. 🐳🍉
//غوني
اترك تعليق