اليوم حنتكلم عن البحث في Elasticsearch، واللي هو يعتبر السبب الاساسي لوجود هذه التقنية. المقالة تفترض انك تعرف اساسيات عن قواعد البيانات وعندك فكرة عن تطوير البرمجيات وقيد اتعاملت مع live production systems، وكمان تفترض انك قرأت الجزء الاول من المقالة. 😉
المقالة هذه هي الجزء الثاني من سلسلة مقدمة في Elasticsearch. تقدر تقرأ الجزء الأول هنا: Elasticsearch الجزء الأول: قاعدة بيانات تجي مع بطارياتها، ولكن…
ايش حنشوف ونتعلم سوااليوم؟
نقطة مهمة: الامثلة هنا في كل السلسلة تفترض على انه عندك Elasticsearch يشتغل، وجميع الأمثلة مكتوبة على Kibana Dev Tools.
تقدر تعرف اكثر هنا
كيف استخدم أهم ميزة: البحث - Search؟ 🔍
تعتبر ميزة البحث هي الركيزة الأساسية في Elasticsearch، وتمثل الفارق الرئيسي بينه وبين قواعد البيانات الأخرى، خصوصاً عندما يتعلق الأمر بالبحث في النصوص. Elasticsearch يوفر قدرات بحث متقدمة، بما في ذلك البحث الـfuzzy، اللي يقدر التعامل مع الأخطاء الإملائية والتنوع اللغوي، مما يجعله أداة قوية جداً في العثور على المعلومات حتى عندما لا تكون النصوص متطابقة تماماً.
انواع البحث
عند استخدام Elasticsearch، هناك عدة أنواع من عمليات البحث يمكن استخدامها بناءً على الاحتياجات المختلفة، منها تعتمد على دقة النتائج ومنها تحاول تقرب لك النتائج اللي قد تكون خطا لكن قريبة بالعنية. خلينا نستكشفها كلها:
Term-Level Search
متى يستخدم: هذا النوع من البحث مثالي عندما تحتاج إلى مطابقة دقيقة للنصوص مثل البحث عن كلمات مفتاحية أو أرقام محددة. وغالبا يكون يستخدم على الـkeywords
مثال:
GET /my_index/_search
{
"query": {
"term": {
"status": "active"
}
}
}
عند استخدام term مع حقل keyword، يقوم Elasticsearch بالبحث عن القيمة المطابقة تماماً، بينما عند استخدامه مع حقل text، لا يعمل بالشكل المطلوب لأن النصوص تحتاج لتحليل قبل البحث.
الفرق بين keyword وtext: مثل ما قلنا في اول مقالة في السلسلة، الـkeyword يتم استخدامه للمطابقات الدقيقة، بينما text يتم تحليله وبالتالي يكون البحث فيه مختلف ويحتاج تحليل. فكر فيها، لو تحتاج مطابقة دقيقة عشان تبحث عن مطابقة ميثالية لـstrings تقدر تستخدم اي نوع قاعدة بيانات وحتفي بالغرض بالكامل.
البحث بالنصوص الكاملة (Full-Text Search)
تخيل إنك عندك مكتبة كبيرة مليانة كتب ومقالات، وتبغى تبحث فيها عن جملة معينة أو حتى موضوع محدد. هنا يجي دور البحث بالنصوص الكاملة في Elasticsearch، واللي هو واحد من أقوى أنواع البحث اللي تقدر تستخدمه لما تحتاج تبحث في نصوص طويلة.
متى نستخدم Full-Text Search؟
هذا النوع من البحث مثالي لما تكون محتاج تبحث في نصوص طويلة مثل مقالات، وصف منتجات، أو حتى محتوى صفحات ويب.
Elasticsearch ما يبحث في النص حرفيًا، لكنه يحلل النص (باستخدام شيء اسمه analyzer، حنتكلم عنه في الجزء الثالث من السلسلة) ويقسمه لكلمات مفتاحية يقدر يفهمها. بعد كدا، يبدأ يطابق الكلمات اللي تبحث عنها مع البيانات المخزنة عنده.
خلينا نتكلم عن أشهر ثلاث طرق للبحث في النصوص الكاملة:
match
هذه الطريقة تستخدم لما تبغى تبحث عن جملة معينة بعد ما يتم تحليلها. يعني لو عندك وصف لمنتج وتبغى تدور عن المنتجات اللي مكتوب فيها مثلاً “quick brown fox”، تقدر تستخدم match.
مثال:
GET /products_index/_search
{
"query": {
"match": {
"description": "quick brown fox"
}
}
}
في هذا المثال، احنا نبحث في الـindex اسمه products_index عن وصف المنتج اللي فيه الكلمات “quick brown fox”. طبعًا Elasticsearch بيحلل النص قبل ما يبحث، عشان يتأكد إنه يبحث بطريقة ذكية.
مثال على النتيجة:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.3862944,
"hits": [
{
"_index": "products_index",
"_id": "1",
"_score": 1.3862944,
"_source": {
"title": "Fox Toy",
"description": "A quick brown fox jumps over the lazy dog.",
"price": 29.99
}
},
{
"_index": "products_index",
"_id": "2",
"_score": 1.2039728,
"_source": {
"title": "Fox Plushie",
"description": "The quick brown fox is a classic example in grammar books.",
"price": 15.99
}
}
]
}
}
حلو، النتيجة كلام كثير مره، خلينا نفككها حبة حبة:
- took: الوقت اللي أخذه البحث بالملي ثانية.
- _shards: معلومات عن الشرائح اللي تم البحث فيها (حنتكلم عنها لاحقًا).
- hits.total.value: عدد النتائج اللي لقاها Elasticsearch.
- hits.max_score: أعلى درجة تطابق بين النتائج والـquery.
- _score: مقياس لتطابق النتيجة مع البحث (كل ما زاد الرقم، زاد التطابق).
- _source: هو بيانات الوثيقة اللي طلعها البحث، وفي هذا المثال لقى لنا نتيجتين بمواصفات مختلفة.
النتائج في Elasticsearch مقسمة لثلاث اقسام:
- معلومات عن عملية البحث: ويكون فيها لو صار timeout واكبر نتيجة مشابهة للـquery وعدد الـdocuments المطابقة
- بيانات عن كل مستند مثل الـ_score او نتيحة المطابقة
- الـdocument نفسه ويكون داخل _source
multi_match
هذا البحث مشابه للـmatch، لكنه يبحث في أكثر من حقل بنفس الوقت. فلو عندك حقل للوصف وحقل للعنوان وتبغى تبحث في الاثنين مع بعض، استخدم الـmulti_match.
GET /my_index/_search
{
"query": {
"multi_match": {
"query": "quick brown fox",
"fields": ["description", "title"]
}
}
}
هنا نبحث عن “quick brown fox” في الحقول description وtitle في نفس الوقت، ونشوف النتائج اللي تطابق.
مثال لنتيجة البحث من Elasticsearch
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1.5,
"hits": [
{
"_index": "products_index",
"_id": "3",
"_score": 1.5,
"_source": {
"title": "Quick Fox",
"description": "it jumps over lazy dogs",
"price": 19.99
}
},
{
"_index": "products_index",
"_id": "1",
"_score": 1.3862944,
"_source": {
"title": "Fox Toy",
"description": "A quick brown fox jumps over the lazy dog.",
"price": 29.99
}
},
{
"_index": "products_index",
"_id": "2",
"_score": 1.2039728,
"_source": {
"title": "Fox Plushie",
"description": "The quick brown fox is a classic example in grammar books.",
"price": 15.99
}
}
]
}
}
match_all
أما لو تبغى ترجع كل النتائج الموجودة في الـindex بدون أي فلترة أو شروط، تقدر تستخدم match_all. مفيد لو تبغى تطلع كل البيانات بغض النظر عن محتواها.
يعني تخيل نفسك بتسوي <select * from <TABLE_NAME
{
"query": {
"match_all": {}
}
}
بشكل عام، الـFull-Text Search يقدر يكون أداة قوية جدًا بفضل الـparameters اللي يعطيها لك Elasticsearch. تقدر تسوي عمليات بحث متقدمة وتستخرج البيانات اللي تحتاجها بسرعة وفعالية. ولو حبيت تتعمق أكثر، تقدر تشوف كيف Elasticsearch يحسب الـ_score ويعطيك النتائج المرتبة على حسب تطابقها مع استعلامك؛ حنغطي كثير عن كيف يشتغل Elasticsearch في الجزء الثالث من هذه السلسلة.
Compound Queries
في بعض الأحيان، البحث البسيط ما يكفي. ممكن تحتاج توصل لنتائج أكثر دقة وتعقيد باستخدام مجموعة من الشروط المترابطة. هنا يجي دور الاستعلامات المركبة (Compound Queries) في Elasticsearch، اللي تعطيك المرونة والقوة لبناء استعلامات معقدة تلبي احتياجاتك بالضبط.
ليش نستخدم Compound Queries؟
تخيل إنك عندك قاعدة بيانات فيها منتجات متنوعة، وتبغى تبحث عن المنتجات اللي تنطبق عليها شروط معينة. ممكن تبغى المنتج يكون بسعر معين، وفيه كلمات مفتاحية محددة، ومصنف ضمن فئة معينة. باستخدام الـCompound Queries، تقدر تجمع كل هذي الشروط في استعلام واحد وتتحكم بشكل كامل في نتائج البحث.
AKA. تقدر تكتب query معضّلة.
أنواع الـCompound Queries خلينا نتعمق في أشهر وأهم نوع من الـCompound Queries في Elasticsearch: الاستعلام المنطقي (Boolean Query).
الاستعلام المنطقي (Boolean Query)
أكثر الأنواع استخدامًا، لأنه يسمح لك تبني query تتضمن عدة شروط ويحدد كيفية ارتباطها ببعض. الـBoolean queries تعتمد على أربعة مكونات رئيسية:
must: الشروط اللي لازم تتحقق. يعني لو عندك query وفيه شرط في الـmust، لازم الوثيقة تطابق هذا الشرط عشان تظهر في النتائج.
must_not: الشروط اللي لازم ما تتحقق. لو الوثيقة تطابق أي شرط في الـmust_not، ماراح تظهر في النتائج.
should: الشروط الاختيارية. يعني لو الوثيقة تطابق هذي الشروط، حتزيد فرصها في الظهور بنتيجة أعلى، لكن مو لازم كل الشروط تتحقق.
filter: الشروط اللي لازم تتحقق، لكنها ما تأثر على درجة الوثيقة (_score). بمعنى إن الوثيقة لازم تطابق شروط الفلترة، لكن التقييم النهائي ما يتغير بناءً على هذه الشروط.
توضيح مهم: مو لازم تستخدم كل الأربعة عشان تكون الـBoolean query صحيحة.
مثال: خلينا نشوف كيف نقدر نبني Boolean Query تجمع بين هذي المكونات:
{
"query": {
"bool": {
"must": [
{ "match": { "category": "electronics" }},
{ "range": { "price": { "gte": 100, "lte": 1000 }}}
],
"must_not": [
{ "match": { "brand": "brandX" }}
],
"should": [
{ "match": { "features": "wireless" }},
{ "match": { "features": "bluetooth" }}
],
"filter": [
{ "term": { "in_stock": true }}
]
}
}
}
ايش يسوي المثال اللي فوق بالضبط؟ 🤔
must: المنتج لازم يكون في فئة electronics، و السعر لازم يكون بين 100 و 1000.
must_not: ما نبغى منتجات من العلامة التجارية brandX.
should: لو المنتج يحتوي على ميزة wireless أو bluetooth، حيكون له أفضلية في الترتيب.
filter: المنتج لازم يكون متوفر في المخزون (in_stock = true).
لاحظ كان يمدينا بكل سهولة نحط اكثر من شرط في مصفوفة (array) ونخلي بحثنا يعتمد على اكثر من شيء في اكثر من حقل او field. الناتج اللي بيرجع لنا من Elasticsearch حيكون نفس شكل الناتج اللي موجود في المثال فوق
خلينا نطلع Insights 🧠
واحدة من احلى الاشياء في Elasticsearch هي انه يجي معاه كثير من الخواص اللي تساعدك على تحليل وفهم بياناتك بشكل سهل وسريع. هذا النوع من الـqueries يسمى بـAggregations، وفي لها انواع مختلفة حتكلم عنها اكثر. لكن اول، خلينا نفهم ايش تسوي الـaggreagtions
Aggregations: نوع من انواع الـqueries يساعدك على سحب البياتات وفلترتها، تلخيصها، وتقسيمها بأي شكل تحبه. وتقدر كمان تحسب بعض الاحصائيات اللي تساعدك تفهم البيانات بشكل افضل واعمق.
انواع Aggregations
في اكثر من نوع Aggregations في Elasticsearch، ولكن الاهم والاكثر استخداما هي الـMertic و الـBucket، خلينا نتعرف على كل واحدة فيها اكثر ونشوف ايش الفائدة منها.
Metric Aggregations
نبدأ مع الـMetric Aggregations، وهي الـaggregations اللي تعطيك احصائيات على بياناتك، على سبيل المثال: كم متوسط سعر المنتجات في متجرنا؟ أو ايش القيمة اللي في الـ75th percentile؟
طريقة كتابة الـmetric aggregations سهلة وقريبة من اللي متعودين عليه، خلينا نشوف مثال سوا:
GET /my_index/_search
{
"aggs": {
"average_price": {
"avg": {
"field": "price"
}
}
}
}
في هذا المثال نبغا نعرف متوسط القيم في الحقل اللي اسمه price في الـindex اللي اسمه my_index. وسمينا الحقل اللي بيكون فيه المتوسط بـaverage_price
لاحظ هنا شيئين، الـendpoint لسى نفسها، التغيير في الـbody حق الـrequest بس. وكمان اعلى مستوى في الـbody صار "aggs" بدلا من "query" في كل الامثلة الماضية.
وهذا مثال للنتيجة اللي تصدر لنا:
{
"took": 15,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1000,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"average_price": {
"value": 249.5
}
}
}
هنا نقدر نشوف كم شيء:
- hits.value يورينا عدد الـdocuments اللي استخدمها في الحسبة، في حالتنا 1,000 document
- aggregations هو الـobject اللي بنلاقي فيه الاحصائيات اللي طلبناها من الـquery. ونقدر نشوف ان جوته في الحقل الجديد اللي عرفناه اللي اسمه
average_priceمع متوسط الاسعار (249.5) فيvalue.
الـmetric aggregations كثيرة، هذه قائمة مختصرة جدا لاحصائيات ثانية تقدر تطلعها بكل سهولة:
- sum: عشان تحسب مجموع القيم في حقل معين.
- min: عشان تلاقي أقل قيمة في الحقل.
- max: عشان تلاقي أكبر قيمة في الحقل.
- count: عشان تعد كم document عندك.
Bucket Aggregations
في الـBucket Aggregations، بدل ما نطلع احصائية معينة، تقدر تقسم البيانات لعدة مجموعات (أو Buckets) على حسب معيار معين. مثلا، تقدر تقسم بياناتك حسب التواريخ، أو حسب الفئات، أو حتى حسب قيم معينة في حقول معينة. اقرب مثال لها هو الـGroup by في الـrelational models، ولكن الـBucket Aggregations فيها خواص اكثر وأقوى.
خلينا نشوف مثال bucketing او تقسيم مع بعض:
GET /my_index/_search
{
"aggs": {
"products_by_category": {
"terms": {
"field": "category.keyword"
}
}
}
}
هذا الـAggregation بيقسم لك الوثائق اللي عندك حسب الحقل category.keyword. يعني كل فئة من الفئات اللي عندك في البيانات حيكون لها مجموعة (أو bucket) خاصة فيها.
ومثل الـmetric aggreagtions، الـbucket aggregations تتوقع مننا اننا نعرّف حقل جديد عشان تظهر النواتج تحته، هنا سمينا الحقل الجديد products_by_category.
لاحظ اننا استخدمنا الـkeyword وليس الحقل بشكل مباشر، لان الـbuckets ما تسمح لنا نسوي bucketing بنصوص قابلة للتحليل، لازم تكون نصوص معرّفة.
هذا مثال للناتج:
{
"took": 15,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1000,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"products_by_category": { // 👈 الناتج اللي يهمنا
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "electronics",
"doc_count": 500
},
{
"key": "clothing",
"doc_count": 300
},
{
"key": "books",
"doc_count": 200
}
]
}
}
}
الناتج فوق يورينا انه عندنا 3 انواع من المنتجات في متجرنا، نقدر نشوف كل نوع عدد الـdocuments اللي تنتمي لهذا النوع.
وبرضه عندنا اشكال كثيرة للـbuckets تقدر تتطلع عليها هنا وتستخدمها، هذه أمثلة شائعة على الـBucket Aggregations:
- date_histogram: لتقسيم الوثائق حسب التواريخ (مثلا كل يوم، كل شهر، كل سنة).
- range: لتقسيم الوثائق حسب نطاقات قيم معينة (مثلا نطاقات أسعار).
- histogram: لتقسيم الوثائق حسب نطاقات قيم متساوية.
Pipeline Aggregations
الـPipeline Aggregations هي Aggregations أكثر تقدمًا. الفكرة فيها إنها تأخذ الناتج من Aggregation آخر (سواء bucket او metric) وتقوم بعملية إضافية عليه. مثلا، عندنا index فيه العمليات اللي صارت في متجرنا الالكتروني، كل document يمثل عملية.
نبغا نسوي pipeline aggregation يحسب لنا عمليات البيع باليوم، بعدين يحسب الـtotal revenue، وكمان يحسب متوسط سعر المنتج لكل يوم (باعتبار ان المنتجات لها اسعار مختلفة).
يلا نطبق المثال اللي فوق ونشوف كيف نقدر نشبك aggregations متعددة ببعض:
GET /my_index/_search
{
"size": 0,
"aggs": {
"sales_by_day": {
"date_histogram": {
"field": "transaction_date",
"calendar_interval": "day"
},
"aggs": {
"total_revenue": {
"sum": {
"field": "product_price"
}
},
"average_product_price": {
"avg": {
"field": "product_price"
}
}
}
}
}
}
هذه بالراحة اعقد query كتبناها الى الآن، ولكن صرنا نعرف كفاية عشان نفككها سوا ونفهمها. 🧠
خلينا نشوف ايش تقول جزء بجزء:
- date_histogram: يقوم بتقسيم البيانات على أساس الأيام.
- total_revenue: يسوي جمع (sum) لكل العمليات في كل يوم يوم. (باستخدام ناتج الـaggregation اللي قبله).
- average_product_price: يحسب متوسط قيمة كل منتج انباع لكل يوم، عشان نعرف اذا في يوم قدرنا نجيب دخل اكثر ولكن بعنا بضاعة اقل (بسعر اعلى).
خلينا نشوف مع بعض كيف Elasticsearch حيقدر يعطينا اللي نبغاه بطريقة سهلة القراءة:
{
"aggregations": {
"sales_per_day": {
"buckets": [
{
"key_as_string": "2024-08-20",
"key": 1724102400000,
"doc_count": 5,
"total_revenue": {
"value": 500.0
},
"average_product_price": {
"value": 100.0
}
},
{
"key_as_string": "2024-08-21",
"key": 1724188800000,
"doc_count": 8,
"total_revenue": {
"value": 920.0
},
"average_product_price": {
"value": 115.0
}
}
]
}
}
}
طبعا نقدر نشوف ان فعلا قسم البيانات الى ايام (يومين في هذا المثال)، وحسب الدخل الكلي ومتوسط سعر السلعة لكل يوم. ونقدر كمان نشوف البيانات او الـdocuments اللي كانت في حسبة كل يوم باستخدام خيار الـsource_ في الـquery. 👍
فمثل ما تشوف، الـpipeline aggregations تمكنا ندمج بين الـmetric والـbucket بشكل سهل وسلس ويفتح لنا خيارات لا نهائية.
تشغيل Elasticsearch 🔄
تشغيل Elasticsearch هو اكبر تضحية عشان تستخدم كل الميزات الحلوة اللي اتكلمنا عنها فوق. فيه أشياء لازم تفهمها عشان تقدر تستفيد من قوة Elasticsearch الكاملة. هنا حنتكلم عن الـCluster و الـshards وليش هذه المفاهيم مهمة عشان تضمن أداء عالي وموثوقية.
الـElasticsearch Cluster هي مجموعة من الـnodes، كل واحد منها يعتبر نسخة من Elasticsearch ويقدر يشيل جزء من البيانات أو كل البيانات على حسب إعداداتك. الـCluster يشتغل كمجموعة واحدة بحيث لو صار مشكلة في node معين، بقية الـnodes تغطي مكانه. خلينا الآن نعرف الـnodes وانواعها عشان تكون الافكار واضحة:
- Node: هو جهاز كمبيوتر أو instance ضمن الـCluster يشغل Elasticsearch. كل Node ممكن يكون عنده دوره معين:
- Master Node: يتحكم في عمليات الكلاستر مثل إضافة أو إزالة nodes، وتقسيم البيانات.
- Data Node: يخزن البيانات ويشغل عمليات القراءة والكتابة.
- Ingest Node: يعالج البيانات قبل تخزينها.
- Coordinating Node: يوزع الطلبات على الـnodes الباقية.
Shards
البيانات في Elasticsearch تتخزن في الـindex. لكن، لو عندك بيانات كثيرة، تخزينها كلها في مكان واحد ممكن يسبب مشاكل في الأداء. هنا تجي فكرة الـShards.
Shard هي قطعة من البيانات المتقسمة داخل الـindex. كل index ممكن يتقسم لعدة shards، وكل shard يتخزن في node مختلفة. هذا التقسيم يخلي Elasticsearch يقدر يتعامل مع بيانات ضخمة بسرعة وكفاءة لانها بيحث في اكثر من node في نفس الوقت.
والـshards لها نوعين:
- Primary Shard: النسخة الأساسية من البيانات.
- Replica Shard: نسخة مطابقة من الـPrimary Shard. هذه النسخة موجودة عشان تغطي لو صار أي مشكلة في الـPrimary Shard.
الـshards والـindex كلهم يحووا على الـdocuments, ولكن واحد فيهم يحتويهم احتواء فيزيائي والثاني منطقي.
تقدر تتخليها نفس الـtable والـdisk في قواعد البيانات الاخرى، بحيث ان الـtable “تحتوي على بيانات” ولكن هذا تعريف منطقي وليس حرفي، لا اللي يحتوي على البيانات هو الـdisk.
وعشان يوضح المفهوم اكثر، هذه صورة توضح العلاقة بين العناصر اللي تكون الـElasticsearch cluster (cluster, node, index, shard)
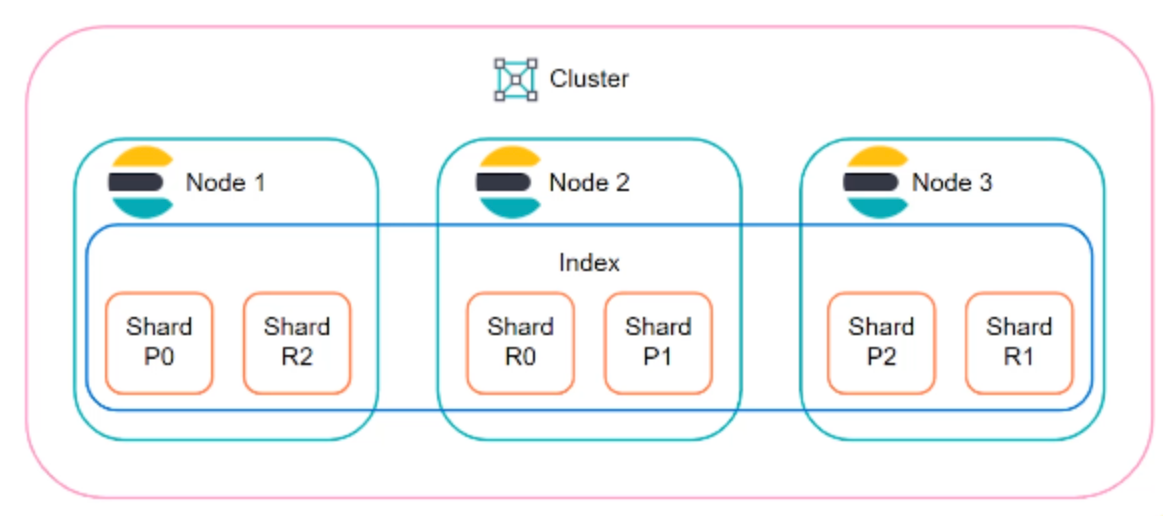
صحة الـCluster
صحة الـCluster شيء مهم جدًا. لازم تتابع حالة الـCluster بشكل دوري عشان تتأكد إنه يشتغل بكفاءة. صحة الـCluster ممكن تكون:
- Green: كل الشاردز والـreplicas شغالة بدون مشاكل.
- Yellow: الـPrimary shards كلها شغالة، لكن بعض الـReplica shards مو شغالة. يعني البيانات كلها موجودة لكن في حالة حدوث أي مشكلة، النسخ الاحتياطية مو كاملة (يعني ألحق على نفسك 🏃🏻♂️).
- Red: بعض الـPrimary shards مو شغالة. هذا يعني إن فيه بيانات ما تقدر توصل لها.
تقدر تشوف صحة الـcluster اما عن طريق الـUI في Kibana، او عن طريق الـAPI التالي:
GET /_cluster/health
والنتيجة حتكون تفصيلية وواضحة، ومن خلالها تقدر تعرف وضع الـcluster وايش المفروض تسوي (اذا يحتاج تسوي اي شيء):
{
"cluster_name": "my_cluster",
"status": "yellow",
"timed_out": false,
"number_of_nodes": 3,
"number_of_data_nodes": 3,
"active_primary_shards": 5,
"active_shards": 10,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 2,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 83.33333333333333
}
التقنيات المستخدمة في Elasticsearch
Elasticsearch مكتوب بلغة Java ويعتمد بشكل كبير على مكتبة Lucene اللي توفر كل العمليات الخاصة بالبحث. Lucene بحد ذاتها مكتبة قوية جدًا، لكن صعبة الاستخدام مباشرة. هنا يجي دور Elasticsearch اللي يقدم طبقة تشغيلية فوق Lucene، ويضيف REST APIs تخليك تتعامل مع كل العمليات بسهولة كبيرة.
- Lucene: المحرك الأساسي اللي يعتمد عليه Elasticsearch عشان يخزن البيانات ويبحث فيها.
- REST APIs: تسهل عليك الوصول للبيانات وتنفيذ كل العمليات بدون ما تحتاج تعرف تفاصيل عن Lucene.
مين تحتاج في فريقك؟
عشان تشغل Elasticsearch بكفاءة، من الافضل يكون عندك ناس عندهم خبرة في:
- Java: لأن Elasticsearch مبني على Java، فلازم تعرف كيف تعدل إعدادات JVM، وتضبط الـheap memory، وغيرها من إعدادات النظام اللي تضمن أداء عالي.
- Distributed Systems: لأن Elasticsearch يعتمد على انه يشتغل بشكل distributed، ففهمك لكيفية عمل الأنظمة الموزعة حيكون إضافة قوية للفريق.
الزبدة 🧈
والله ابغا اخدمك، بس صعب اكتب زبدة لهذه السلسلة. حاول تقراها. :) 3>
شكرا جدا عشان وصلت لهنا! احترم وقتك الثمين واتمنى انك استمتعت في القراءة. 🙏
الاضافة القادمة للسلسة حتكون عن كيف Elasticsearch يشتغل من وراء الكواليس، كيف يحلل النصوص ويفهمها عشان يعطينا الخواص السحرية هذه. 🪄
حاكون ممتن لو ساعدتني على نشر العمل هذا عن طريق ارسال المدونة لاحد ممكن يستفيد منها، فالاخير الهدف هو نشر محتوى عربي تقني بجودة عالية مجانا؛ مساعدتك لي في هذا الهدف يعني لي الكثير. 🐳🍉
//غوني
اترك تعليق