اليوم حنغوص زيادة في (ES) Elasticsearch، الجميل، وحنشوف كيف تشتغل هذه التقنية اللطيفة. المقالة تفترض انك تعرف اساسيات عن قواعد البيانات وعندك فكرة عن تطوير البرمجيات وقد تعاملت مع live production systems، وقراءتك للمقالتين الاولى للسلسة حتساعدك كثير. 👍
المقالة هذه هي الجزء الثالث من سلسلة مقدمة في Elasticsearch.
تقدر تقرأ الجزء الأول هنا: Elasticsearch الجزء الأول: قاعدة بيانات تجي مع بطارياتها، ولكن…
والجزء الثاني هنا: Elasticsearch الجزء الثاني: خلينا نعيد تعريف البحث في قواعد البيانات للأبد
ايش حنشوف ونتعلم سوااليوم؟
- ايش يصير لما تدخل البيانات في Elasticsearch؟ 💾
- كيف يفهم Elasticsearch المعلومات اللي ادخلها؟ 🧠
- ايش يصير لما اكتب Query في Elasticsearch؟ ☁️
- طيب لو ابغا اعدل الـAnalyzer بحسب احتياجي؟ 📝
- ايش وضع Elasticsearch مع العربي؟ 🤔
- Elastic Stack: كيف نقدر نشغل ES في بيئة متكاملة؟ 🤹♂️
نقطة مهمة: الامثلة هنا في كل السلسلة تفترض على انه عندك Elasticsearch يشتغل، وجميع الأمثلة مكتوبة على Kibana Dev Tools.
تقدر تعرف اكثر هنا
ايش يصير لما تدخل البيانات في Elasticsearch؟ 💾
لما تدخل بيانات جديدة في Elasticsearch، أول شيء يصير هو تحديد كيفية التعامل مع هذه البيانات. في Elasticsearch، العملية تبدأ من الـmapping. الـMapping هو زي القالب اللي يحدد كيف Elasticsearch يتعامل مع كل حقل في الـdocument اللي أرسلته.
إذا كان الحقل يحتوي على بيانات نصية (من نوع text)، مثل وصف المنتج أو عنوان المقالة، فإن Elasticsearch ما يقدر يحفظها زي ما هي. لازم البيانات النصية تمر بمراحل الـtext analysis لتحويلها إلى شكل يمكن البحث فيه. هذا يعني إنه Elasticsearch يحلل النص ويقسمه إلى أجزاء أصغر (tokens)، ويسوي عمليات إضافية مثل التحويل إلى حروف صغيرة (lowercasing) أو حذف الكلمات الشائعة اللي ما تضيف قيمة كبيرة للبحث (مثل “the” و”and”).
أما لو كانت البيانات من أي نوع ثاني زي الأرقام (integer أو float)، التواريخ (date)، أو القيم المنطقية (boolean)، فيتم حفظها مباشرة من غير ما تمر بمراحل الـanalysis. ليش؟ لأن البحث في هذه الأنواع من البيانات ما يحتاج عمليات تحليل معقدة زي النصوص، وممكن يتم بسرعة وكفاءة باستخدام الفهرسة المباشرة.
Type Inference: تحديد النوع تلقائيًا
لو ما كان عندك Mapping واضح في الـindex أو لو كان الحقل جديد ما قد أضفته من قبل، Elasticsearch يحاول يتعرف على نوع البيانات تلقائيًا باستخدام الـType Inference. مثلاً، لو أضفت قيمة للحقل وكانت على شكل أرقام، Elasticsearch يفترض أنها من نوع “Integer” أو “Float” حسب الصيغة. هذا التمييز التلقائي يعتبر ميزة قوية جدًا، لأنه يوفر عليك جهد إعداد الـMapping بشكل يدوي لكل حقل.
لكن هذه الميزة لها عيوبها. على سبيل المثال، لو كان عندك حقل نصي فيه أرقام مثل “12345”، Elasticsearch ممكن يخطئ ويعتبر هذا الحقل “Integer” بدلاً من “Text”. المشكلة هنا إنه لو حبيت تضيف قيمة نصية فيما بعد، حتواجه مشاكل لأن الـMapping للحقل محدد مسبقًا على إنه “Integer”. الحل في هذه الحالة يكون إما بإعداد الـMapping يدويًا أو بتغيير نوع الحقل بشكل صريح قبل ما تضيف بيانات.
كيف يفهم Elasticsearch المعلومات اللي ادخلها؟ 🧠
تمر كل معلومة من نوع text في ES بشي يسمى بـAnalyzer، الـanalyzer له مهمتين اساسية وهي تقسيم النص، وتحويله لشكل سهل البحث. والآن، خلينا نتكلم عن خطوة من هذه الخطوات عشان توضح المعلومة اكثر.
Tokenization:
أول خطوة في تحليل النصوص داخل Elasticsearch هي تقسيم النصوص إلى وحدات صغيرة تُسمى tokens. هذه الوحدات عادة تكون كلمات فردية أو أجزاء من الكلمات. مثلاً، إذا كان عندك نص “The quick brown fox”, فإن الـtokenizer يقسمه إلى tokens مثل:
- The
- quick
- brown
- fox
Normalization:
بعد ما يقسم النص إلى tokens، يجي دور الـNormalization. هذا المصطلح يشمل عدة عمليات زي الـlowercasing، اللي يحول كل الحروف إلى حروف صغيرة عشان يصير البحث غير حساس لحالة الأحرف (case-insensitive). كمان فيه عملية الـStemming، اللي تشيل أجزاء من الكلمات زي “ing” أو “ed” بحيث تقدر تبحث عن “running” وتلقى نتائج لـ “run”.
كيف يصير التقسيم والتحويل؟
طريقة عمل الـAnalyzer تتم في 3 خطوات: Character filter, tokenization, & token filters
معلومة ثانية مهمة: كل الخطوات اللي حنتكلم عنها عنها تحصل بالترتيب هذا، واضافة على ذلك، كلها يمكن تغييرها بحسب الاحتياج، فحأشرح الاعدادات الافتراضية اللي تجي مع ES عند التشغيل، حتكلم عن تغيير الاعدادات في طيب لو ابغا اعدل الـAnalyzer بحسب احتياجي؟ 📝. والآن، خلينا نتكلم عن الخطوات:
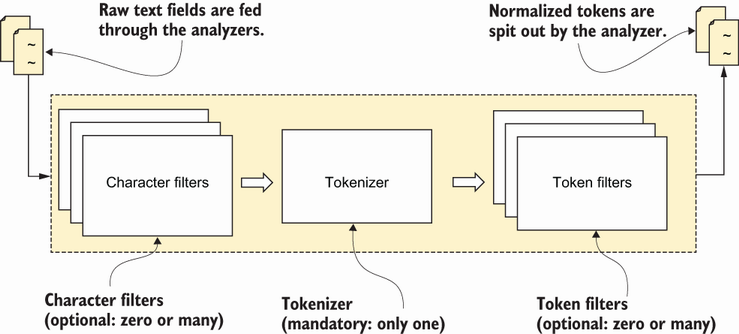
- Character Filter: يكون عنده شغلة وحدة بس، وهي حذف حروف مالها مو مهتمين فيها. مثلا، لو كانت بيانتنا تحتوي على كلمة “description” في بداية كل document.description، نقدر نفلتر هذه الكلمة بكل سهولة لانها متكررة ومالها معنى كبير بالنسبة لنا. هذه الخطوة بالاعدادات الافتراضية فاضية وما تسوي شي. ولكن يمكننا نضيف اكثر من قانون للفلترة
- Tokenizer: شغلته واضحة، يقسم الـtext بحسب قوانين معينة ويخليها مصفوفة. اشهر طريقة لتقسيم الـtext (الافتراضية) هي باستخدام المسافات او الحروف البيضاء (whitesapces). هذا لازم يكون موجود عشان يكون الـanalyzer صحيح، ولا يمكن الا نقسم الـtoken بطريقة واحدة بس
- Token Filters: هنا نقدر نرجع الكلمة لاصلها (stemming)، نخلي كل الحروف صغيرة (lowercasing)، او نغير فيها بأي طريقة ثانية. الخطوة هذه هيا اللي تسوي normalization وتشتغل على كل واحد من الـtoken اللي تطلع من الخطوة الثانية.
بعد خروج البيانات من الـanalyzer، بشكل مشابه للصورة ادناه وتكون جاهزة للحفظ في الـInverted index، واللي هي هيكل البيانات اللي مبنية عليه كل عمليات البحث.
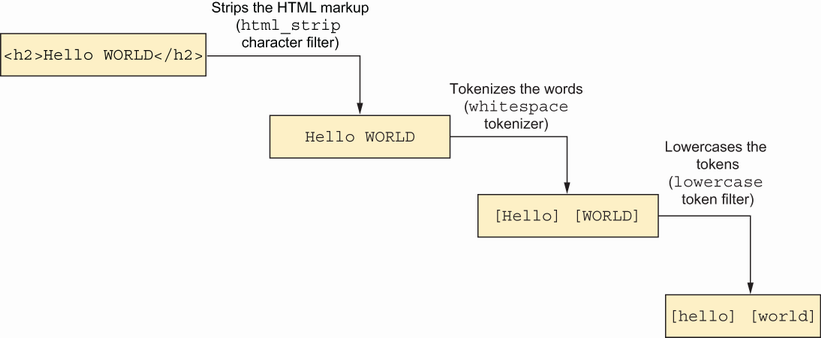
Inverted Index:
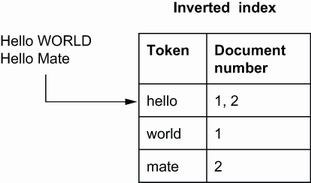
آخر خطوة هي تخزين الـtokens بعد الـnormalization في Inverted Index. هذا هو الأساس اللي يشتغل عليه Elasticsearch عشان يسرع عملية البحث. الـInverted Index يخزن كل كلمة (أو token) ويعمل ربط بين هذه الكلمة والمستندات اللي تحتوي عليها. مثلاً، إذا كانت الكلمة “fox” موجودة في 100 مستند، فإن الـInverted Index يخزن ID كل واحد من الـ100 مستند عشان يقدر يسترجع هذه المستندات بسهولة وسرعة لما تبحث عن كلمة “fox”.
ايش يصير لما اكتب Query في Elasticsearch؟ ☁️
لما تكتب Query في Elasticsearch، العملية تمر بمراحل مشابهة جدًا لما يصير عند إدخال البيانات. الفكرة هنا هي التأكد من أن الاستعلام اللي كتبته يتم تحليله وفهمه بنفس الطريقة اللي تم بها تحليل البيانات في الـIndex عشان نقدر نقارن بشكل صحيح.
تحليل الـquery:
أول شيء يصير هو أن Elasticsearch يمرر الـquery بنفس الـtokenizer والـnormalizer اللي تم استخدامها لتحليل البيانات الأصلية. مثلاً، لو كتبت استعلام للبحث عن “running”, فإنه Elasticsearch يقسم الاستعلام إلى tokens ويحوله إلى الشكل اللي يتناسب مع البيانات اللي في الـIndex.
بعد ما يخلص الـanalysis للـquery وتصير المقارنة اسهل، يستخدم ES خوارزمية تساعده على حساب التشابه (Relevancy Algorithm) بين الـquery وبين الـInverted index الموجود. في الاعدادات الافتراضية، ES يستخدم Best Match 25 (BM25)
Okapi BM25
عشان يقيس مدى تطابق المستندات مع الاستعلام، يستخدم Elasticsearch خوارزمية تُسمى Okapi Best Match 25 (BM25). هذه الخوارزمية تعمل على تحسين نتائج البحث عن طريق حساب مدى أهمية الكلمة في المستندات بالمقارنة مع جميع المستندات في الـIndex. الـBM25 هي نسخة محسنة من TF-IDF، وتعمل على ضمان أن المستندات الكبيرة ما تحصل على وزن غير مستحق فقط لأنها تحتوي على عدد كبير من الكلمات.
تعتمد هذه الخوارزميات على 3 عوامل رئيسية لحساب التشابه، وهي:
- عدد مرات وجود الكلمة في الحقل
- عدد مرات وجودة الكلمة في كل الـindex (او الـcorpus): عشان نعرف لو كانت كلمة نادرة او لا
- طول الحقل: لو كانت الكلمة موجودة مرتين في حقل من 5 كلمات وحقل ثاني من 500 كلمة، حنفضل الحقل الاول
BM25 (و TF-IDF بشكل عام) خوارزمية مشهورة جدا وتستخدم كثير في مهام الـNLP في علم البيانات. لو تبغا تعرف اكثر، هذا فيديو يشرح الخوارزمية بشكل اعمق وبالرياضيات وكل الاشياء الحلوة.
بعد ما نسوي ترتيب للـdocuments بحسب relevancy score اللي طلع لنا، حنرجع هذه الـdocuments في الناتج من الـquery اللي كتبناها.
لو تتذكر، في الجزء الثاني من السلسلة كنا نشوف في الناتج في الـqueries اللي نكتبها حقل يرجع من ES اسمه
score_. هذا الحقل هو القيمة المحسوبة من BM25 وتكون الـdocuments مرتبه باستخدامه. 💡
واحدة من احلى الاشياء في ES انه يسمح لك تغير حتى خوارزمية تحديد الـrelevancy score من BM25 الى خوارزمية ثانية. خلينا نشوف كيف نقدر نغير هذا كله مع بعض.
طيب لو ابغا اعدل الـAnalyzer بحسب احتياجي؟ 📝
مثل ما ذكرت سابقا في المقالة، Elasticsearch يسمح لنا نتحكم بكيفية تحليل البيانات النصية باستخدام ما يُعرف بـ”analyzers.” الـAnalyzer يتكون من ثلاث مراحل أساسية: tokenization، token filtering، وcharacter filtering.
Character Filters
الـCharacter Filters تُستخدم قبل الـtokenization، وهي تعدل النص بشكل عام قبل تقسيمه. مثلاً، لو عندك نص فيه HTML tags (اطالع عليكم ياللي تحبوا الـscraping 👀) وتبغى تشيلها، تقدر تستخدم html_strip filter.
مثال:
لو النص عندك: "Hello <b>world</b>!"
واستخدمت html_strip filter، حيكون الناتج: Hello world!
فيه امكانيات رهيبة من Elasticsearch تسمح لك تسوي فلاتر قوية تقدر تتطلع عليها هنا. فأي شيء ممكن يخطر في بالك من RegEx لاشياء اكثر تعقيد غالبا ممكن تضيفه كـcharacter filter خاص فيك.
Tokenizers
لنوع الافتراضي في Elasticsearch هو الـstandard tokenizer، اللي يقسم النص بناءً على المسافات وعلامات الترقيم. لكن لو احتجت شيء مختلف، تقدر تغير الـtokenizer على حسب احتياجك.
مثال:
لو عندك نص زي:
"Elasticsearch is awesome. Really awesome!"
الـstandard tokenizer حيحول النص إلى:
Elasticsearch
is
awesome
Really
awesome
لكن لو استخدمت whitespace tokenizer، حيقسم النص بناءً على المسافات بس، وحيكون الناتج:
Elasticsearch
is
awesome.
Really
awesome!
لاحظ هنا ان علامات الترقيم مازالت موجودة.
فيه اكثر من 10 tokenizers جاهزة يوفرها Elasticsearch من خارج الصندوق وتقدر تستخدمها على طول؛ تقدر تقدر تتصفحها هنا.
طبعا مافي صح او خطأ هنا، ومافي اي tokenizer احسن من الثاني، كله يعتمد على البيانات اللي تبغا تدخلها في الـindex وكيف تحتاج تبحث فيها.
Token Filters
بعد ما يقسم الـtokenizer النص، نجي للمرحلة الاخيرة وهي الـToken Filters. هنا، نقدر نطبق مجموعة من التعديلات على الـtokens. مثلاً، ممكن نحول كل الكلمات إلى حروف صغيرة باستخدام فلتر lowercase, أو نشيل الكلمات الشائعة مثل “and” و “the” باستخدام stop filter.
مثال: لو عندنا الـtokens:
Elasticsearch
is
awesome
Really
awesome
واستخدمنا الـlowercase filter، حيكون الناتج:
elasticsearch
is
awesome
really
awesome
الامكانيات لهذه الخطوة كبيرة وتحمس، خصوصا ان ES يسمح لنا نضيف اكثر من Token Filter واحد على الـanalyzer اللي نصممه.
تقدر تضيف واحد من عشرات الـbuilt-in token filters اللي موجودة من ES هنا، فيه عندك من تقسيم الـtokens الى N-grams الى synonyms، كلها من غير ما تكتب اي كود. 🚀
تغيير الاعدادات الافتراضية وتخصيص الـanalyzer الخاص بحالتي
تقدر تسوي تشكيلة مناسبة للي تحتاجه لكل Index موجود في ES، وطبعا كل index ممكن يكون له Analyzer واحد يحدد كيف تحفظ البيانات. خلي بالك ان من الافضل (اذا تقدر) تحدد هذه التغييرات من البداية، لان تغيير الـanalyzer يتطلب تسوي Re-indexing. تكلمها عن الـRe-indexing في الجزء الاول من السلسلة.
اول شيء مهم تخليه فالبال، ان قبل ما تروح الطريق اللي يكون مخصص بالكامل، ممكن يكون فيه Analyzer جاهز ومجرب يسوي كل اللي تبغاه (وتكون محددة الـcharacter filters, tokenizer, and token filters حقته كلها بشكل مضمون)، تقدر تتصفح قائمة الـbuilt-in analyzers هنا - الافتراضي هو الـstandard analyzer
لنفترض ان ناسبنا الـstop analyzer من القائمة اللي فوق كل اللي نحتاج نسويه هو التالي:
PUT /my-index
{
"settings": {
"analysis": {
"analyzer": {
"my_stop_analyzer": {
"type": "stop",
"stopwords": ["the", "over"]
}
}
}
}
}
لاحظ اننا هنا نقدر نضيف مصفوفة من الـstop words اللي تناسبنا في اعدادات الـanalyzer، تقدر تشوف كيف ممكن تخصص analyzer معين من الـdocumenta.
والآن، نفترض ان ما عجبك ولا واحد من القائمة اللي فوق، خلينا نشوف كيف نقدر نغير اعدادات الـanalyzer لاي index موجود ونخصص الخطوات على حالتنا بالضبط:
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lowercase", "stop"],
"char_filter": ["html_strip"]
}
}
}
}
في هذا المثال، حطينا whitespace tokenizer، وفلتر lowercase، وفلتر stop للكلمات الشائعة، وفلتر html_strip لزبط النص قبل تقسيمه.
تغيير خوارزمية حساب التشابه
ولو كنت تبغا تغير الخوارزمية المستخدمة في حساب تشابه الكلمات، تقدر كمان تغير BM25 الى واحد من 5 خوارزميات ثانية، او تكتب الخوارزمية الخاصة بيك كـscripted similarity.
ايش وضع Elasticsearch مع العربي؟ 🤔
ولغتي الخالدة، هل لها دعم؟
اتخيل لو انت تقرأ هذه المقالة، ممكن يخطر في بالك سؤال يقول: “طيب هل Elasticsearch يعرف الـstop words العربية مثلا؟”.
على قولة صديقي الاسطوري نواف العقيل: هذا سؤال ما يجي الا من شخص ذهين وفطين وذكي.
الجواب هو نعم، فيه built-in analyzers في Elasticsearch للغة العربية؛ ولو كنت مهتم، هذه قائمة كاملة بكل اللغات المدعومة:
Arabic, Armenian, Basque, Bengali, Bulgarian, Catalan, Czech, Dutch, English, Finnish, French, Galician, German, Hindi, Hungarian, Indonesian, Irish, Italian, Latvian, Lithuanian, Norwegian, Portuguese, Romanian, Russian, Sorani, Spanish, Swedish, and Turkish
كل اللي تحتاج تسويه عشان تضيف analyzer للغة معينة، هو انك تستخدم language analyzer وتكتب اللغة اللي مهتم تستخدمها، مثال:
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"default":{
"type":"arabic",
}
}
}
}
}
ولو تبغا تشوف تغير في هذا النوع وتحط القوانين الخاصة بيك،Elasticsearch حطوا لك التطبيق كامل، بحيث تقدر تنسخه وتضيف/تحذف/تغير في قوانين الـanalyzer وتسوي override على كيفك.
Elastic Stack: كيف نقدر نشغل ES في بيئة متكاملة؟ 🤹♂️
حلو، صار عندنا صورة كويسه عن Elasticsearch وكيف يشتغل، خلينا نسوي zoom-out شويه.
Elasticsearch رهيب ويحل مشكلة واضحة: محرك بحث وتحليل سريع يعتمد على NoSQL ويوفر قدرات قوية في معالجة البيانات النصية.
ولكن عشان يشتغل هذا المحرك بشكل فعال، فيه الحاجة إلى تجميع وتكامل البيانات من مصادر مختلفة، واظهار النتائج للمستخدم بطريقة مرئية تساعد على اتخاذ قرارات بشكل اسهل وتجربة مستخدم افضل.
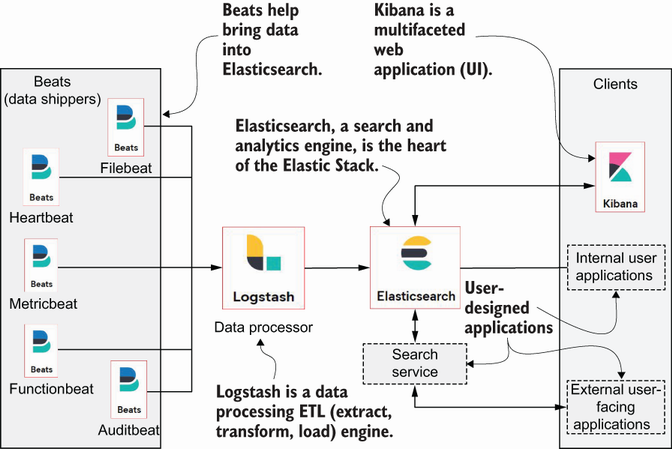
بالبداية كان عندنا “ELK Stack”
كانت (ومازالت عند الكثير) هذه التشكيلة هي التشكيلة الاساسية لتشغيل Elasticsearch بشكل جيد (مع ان محد يحب Logstash وغالبا يتبدل بشي اخف مثل Fluentd). هذا كل حرف من الـELK stack:
- Elasticsearch: قلب النظام، المسؤول عن تخزين البيانات، البحث والتحليل.
- Logstash: لجمع، تحويل، ونقل البيانات من مصادر مختلفة إلى Elasticsearch.
- Kibana: لعرض البيانات بشكل مرئي، مع Dashboards و Charts تساعد على تحليل النتائج. لو كنت تستخدم الـdev tools، discovery عشان تشوف البيانات او تسوي dashboards من البيانات اللي على ES، فانت تستخدم Kibana
لكن مع توسع الحاجة لجمع وتحليل البيانات من أجهزة متعددة بطرق متنوعة، انضافت عائلة Beats إلى الـstack. هذا التغيير أدى إلى إعادة تسمية ELK Stack إلى Elastic Stack.
Beats: اللاعب الجديد في الفريق
Beats هي عبارة عن عائلة من أدوات جمع البيانات الخفيفة (lightweight data shippers) اللي هدفها جمع البيانات من مختلف الأنظمة وإرسالها إلى Logstash أو Elasticsearch مباشرة. فيه اكثر من shipper من Beats، خلينا تعرف على بعضهم:
- Filebeat: متخصص في قراءة ملفات السجلات (logs) من أي نظام، وإرسالها إلى Logstash أو Elasticsearch للتحليل.
- Metricbeat: متخصص في جمع وتحليل المقاييس (metrics) من النظام مثل استخدام المعالج (CPU usage)، الذاكرة (memory)، وغيرها.
- Auditbeat: مسؤول عن مراقبة نشاط النظام وتسجيل الأحداث الأمنية مثل تغييرات الملفات ومراقبة النظام.
فائدة كل جزء في Elastic Stack (غير Elasticsearch)
- Logstash: يعتبر الـmiddleware في Elastic Stack، بحيث يقدر يجمع البيانات من مصادر متعددة، يقوم بمعالجتها وتعديلها (filtering)، ويرسلها بعد ذلك إلى Elasticsearch لتحليلها أو تخزينها. تخيله اداة تسوي ETL.
- Kibana: هو أداة visualization في Elastic Stack، بحيث يوفر واجهة مستخدم متكاملة لإنشاء dashboards، charts، وبيانات إحصائية بشكل سريع وسهل.
- Filebeat: يسهل مهمة جمع البيانات من ملفات السجلات المنتشرة في النظام، سواء كانت من سيرفرات تطبيقات، أنظمة تشغيل، أو أي مصدر آخر يعتمد على ملفات السجلات. غالبا تركبه كـsidecar او تخليه شغال كـprocess في الخادم اللي فيه التطبيق اللي تبغا ترسل منه البيانات
ومع كل هذا، خلصنا سلسلة مقدمة في Elasticsearch. 🎉
شكرا جزيلا لك على القراءة، واتمنى اني قدرت اضيف لك ولو معلومة جديدة من هذه المقالات.
في أمان الله. 👋🏻
كثير من الصور والأمثلة تم اقتباسها من كتاب رائع لـElasticsearch اسمه:
Elasticsearch in Action, 2nd Edition. أقترح جدا انك تقراه لو محتمس تتعمق أكثر في هذه التقنية. أمازون

حاكون ممتن لو ساعدتني على نشر العمل هذا عن طريق ارسال المدونة لاحد ممكن يستفيد منها، فالاخير الهدف هو نشر محتوى عربي تقني بجودة عالية مجانا؛ مساعدتك لي في هذا الهدف يعني لي الكثير. 🐳🍉
//غوني
اترك تعليق